Being agile in 2019
On 22nd and 23rd October, with a few other Touks, I’ve been to a very inspiring event – Agile By Example conference in Warsaw. It’s Read more
 Actuator Metrics
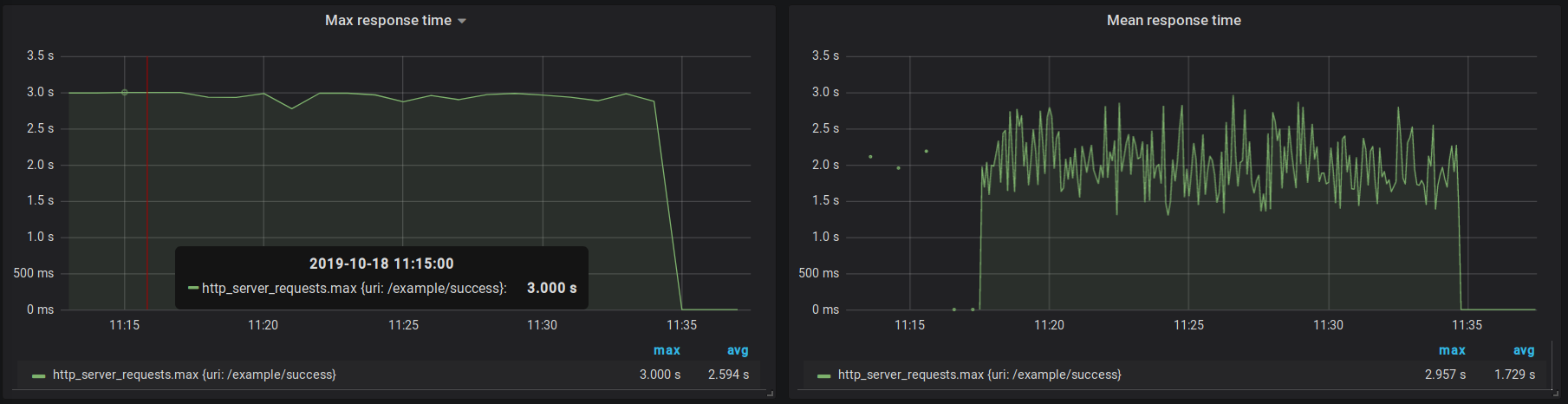
As reported in Michał Bobowski post, we heavily use Spring Boot Actuator metrics system based on Micrometer. It provides a set of practical Read more
Actuator Metrics
As reported in Michał Bobowski post, we heavily use Spring Boot Actuator metrics system based on Micrometer. It provides a set of practical Read more  In March 2019 we held a 2-day hackathon named “Ship IT!” in TouK. I was part of the team developing “Quak” – a 2D Liero/Soldat Read more
In March 2019 we held a 2-day hackathon named “Ship IT!” in TouK. I was part of the team developing “Quak” – a 2D Liero/Soldat Read more