So, here is my list of distinctive features:
BPMN 2.0 support I took quite a lot of time for this spec to arrive, but it’s finally here. The biggest step ahead comparing with BPMN 1.x is execution model – no more BPEL, you can use the same diagram for modelling and execution, and it has proper xsd schema! Of course, it won’t solve all round-trip headaches, but I think it’s quite important improvement. XML describing BPMN 2.0 process consists of nodes definitions and transition definitions: Activiti is one of the first BPM engines offering BPMN 2.0 support. Currently not all nodes are supported, but the list includes:
* exclusive and paralell gateways
-
timer boundary and intermediate events (timer start event almost ready)
-
various tasks: script, user, service, manual, rules, receive
-
error events and handling them
-
subprocesses (both embedded or not) Not all of these nodes are fully defined in spec – e.g. it does not describe how service task invocation should look like. Therefore, Activiti comes with a set of custom extensions. They are meant to be as non-intrusive as possible – to make processes more portable. One of most commonly used are ones for describing service task behaviour: Another useful extension enables to associate html form and candidate user with user task: One of nice features of BPMN 2.0 is also providing xml schema for describing process diagram – aka Diagram Interchange. This enables good engines (such as Activiti ;)) to generate process diagram just on the basis of xml definition – which makes importing processes modelled in some external tool much easier. It looks like this: Maybe not too beautiful, but usable.
Goal of supporting full BPM cycle
- zero coding solutions won’t work
- analysts are needed to model the process, developers are needed to create executable processes, and operations are needed to deploy and monitor them
- each of these groups have their own set of tools which they’re familiar with
- so let’s not reinvent the wheel but encourage them to collaborate but use their set of tools
So, how to achieve this? By creating another web application, of course ;) It’s name is Activiti Cycle and it’s meant to encourage collaboration between business, developers and operations, while allowing each of them to use their own, specific tools in their daily job. It’s more like a federated repository of BPM assets, such as Visio Diagrams, BPMN process definitions, maven process projects, deployment packages and so on. These artifacts can be linked, commented and tracked by various process stakeholders and also transformed.
Easy to embed and extend, also by quasi-REST API

Activiti Probe – screen shows monitoring process instance:

But what if you want to/have to use some other frontend technology? Webapps that I mentioned before are really thin clients – all logic is hidden behind Activiti’s quasi-REST API (I use the word quasi not to be beaten by RESTafarians who will surely point out that Activiti API is just RPC over HTTP…). That means you can embed Activiti in you webapps/OSGi container/any other environment and integrate with frontend webapps using handy JSON/HTTP communication. Which looks more or less like this:
Using (defacto) standards When you create application using Activiti chances are high that you know many (if not all) building blocks & techniques:
- development? Eclipse plugin & maven
- connecting components together? you can choose: spring or (for JEE6 lovers) CDI
- testing? just do your normal TDD (you do it, right? ;)) using Activiti JUnit testing utils
Eclipse plugin includes visual modeler, which enables you to draw executable BPMN 2.0 processes, and fill all needed properties:
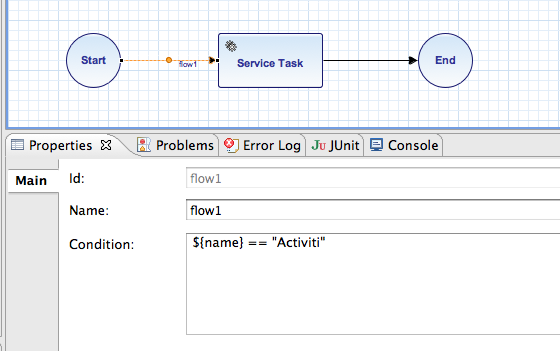
It uses Diagram Interchange format, so process diagram layout will remain the same when displaying process diagram in other applications. Testing is also pretty easy, as Activiti comes with good JUnit support. One of small, but important features is ability to simulate the clock – very handy when dealing with long running tasks.
Good integration capabilities
- Mule ESB – integration is written by MuleSoft
- SpringIntegration, contributed by SpringSource
- last but cetainly not least: Apache Camel – which is contributed by TouK ;) – it’s still work in progress, but I hope to write a blog post soon about integrating Camel & Activiti
This allows to build processes that are closer to orchestration than simple workflows, containing only (or mostly) human tasks. Each of these integration frameworks comes with a vast collection of adapters using all popular (and not so popular) communication protocols. This allows process engine to concentrate on the process, and not on the communication details.
Summary I think it’s quite impressive set of features for a product that is less than year old. And what are Activiti plans for the future? Tom Bayens recently announced that Activiti is going to support some sort of Adaptive Case Management – which is one of top buzzwords in process world. Other goals include:
- asynchronous continuations
- moving towards full support of BPMN 2.0
- extending Activiti Cycle – check Bernd’s Ruecker screencast showing Activiti Cycle approach to handling collaboration between analysts, developers and admins – it’s quite impressive
As for me, I’m finishing adding support for start timer tasks and hope to post something on Activiti-Camel intergration and running Activiti in OSGi environment soon – especially Apache Servicemix – so stay tuned. If you’ve found Activiti interesting, please start with 10 minutes
Getting started guide, and if you know Polish, you can also have a look at my slides from Warsaw JUG presentation Thanks for reading my first post on this blog – hope you liked it.
