So, Russia 2018 World Cup is over. There were lots of good moments, and some worse (especially for us, here in Poland….). But is there something we can learn from this event as programmers? Recently, I had a few free evenings and played a bit with a World Cup API. In this post I want to show you what is Clojure way of dealing with REST APIs and when it beats other languages in this field.
TLDR; The code is on GitHub. Setup is based on Atom and proto-repl package which makes the interactive development experience really pleasant. I highly recommend you follow its installation guide while dealing with my solution.
As a problem to solve, I wanted to find something not trivial, to show some of the Clojure super-powers. Finally, I came up with this:
The problem: find all matches the winning team made a come-back — they lost a goal first, but managed to win.
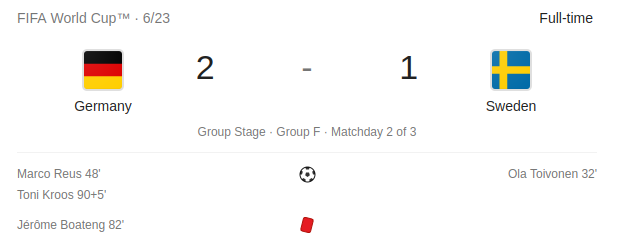
For example Sweden — Germany in a group stage:
Ok, so a good starting point would be getting all matches data for further processing. I’m using clj-http as an http client (with cheshire for json parsing support):
(ns worldcup.matches
(:require
[clj-http.client :as http]))
(def api-root "https://worldcup.sfg.io")
(defn get-all-matches []
(->
(http/get (str api-root "/matches") {:as :json})
:body))
The Clojure philosophy relies heavily on dealing with built-in data structures. In statically typed languages you’d probably start with modelling response JSON as some POJO classes; here you just get a map and can start to investigate it right from the beginning. Huge difference.
One thing that may not be clear in the above code is this -> macro. It is really helpful for nested collection operations. Instead of nesting (xxx (yyy (zzz … calls, you can use both -> and ->> macros to make code similar to e.g. Java equivalent:
(->> lst
(map op1)
(map op2)
(filter p1)
first)
lst.stream()
.map(op1)
.map(op2)
.filter(p1)
.findFirst()
Ok, let’s start to investigate the API response. Using proto-repl it is trivial to examine the value of any data structure straight from your editor. Let’s see the match data — by using Proto REPL: Execute Block action — ctrl+alt+,s shortcut by default:
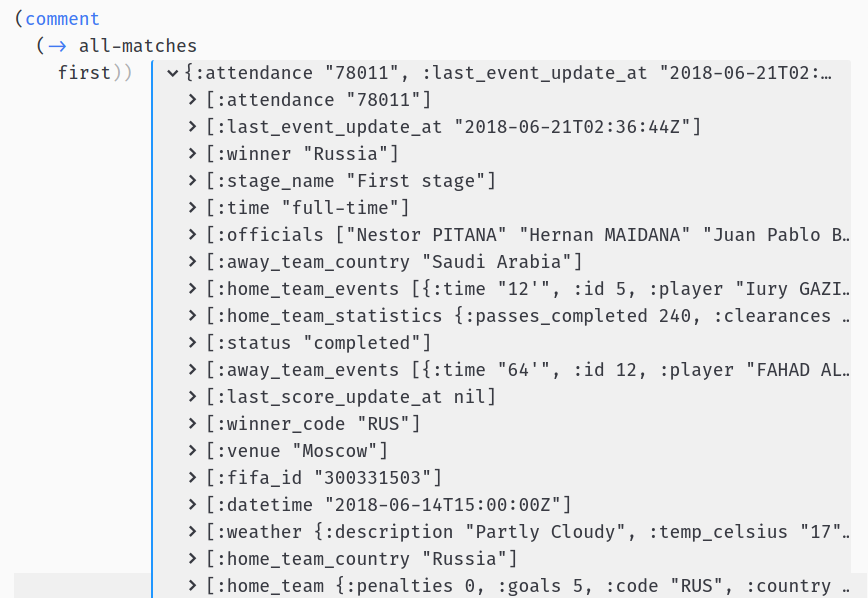
It’s a common practice to wrap interactive invocations into comment macro which makes them ignored when evaluating whole file at once.
Ok, so we have some basic attributes of the match, the number of goals for each team and some team events. Let’s investigate these:
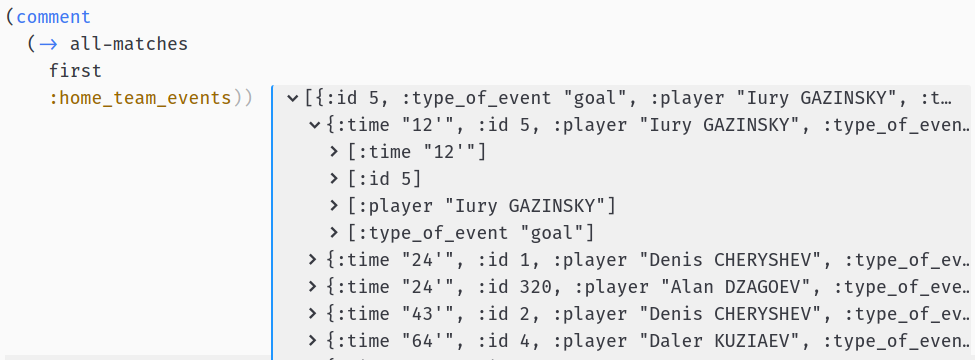
Looks promising — we have all the times of the goals scored by each team. Having this, our algorithm may look like this:
- Get times of goals for each team
- Sort goals by times
- Get the team with the first goal
- Check if the winner is the other team
Let’s start with filtering the goals from team’s events. First, we need to find how to filter goals from match events:
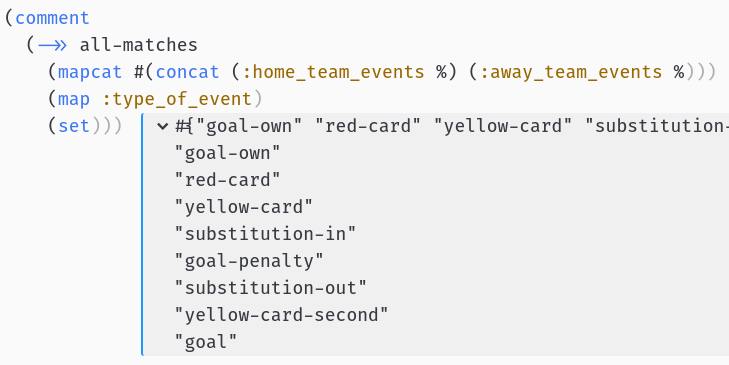
Ok, so we have goal, goal-penalty and goal-own:
defn goal? [e]
(let [type (:type_of_event e)]
(or (= "goal" type)
(= "goal-penalty" type)
(= "goal-own" type))))

Looks good.
We’ll also need the time when the goal was scored and this is in a really strange format, e.g 90'+4'. We need to split on + character, remove ' and trim and then add additional time to get exact minute of the goal:
(require '[clojure.string :as string])
(defn goal-time [t]
(->>
(string/split t #"\+")
(map string/trim)
(map #(string/replace % #"'" ""))
(map #(Integer/parseInt %))
(reduce +)))

EDIT:
Bartek Tartanus (thanks!) found a bug in just adding additional time to half time: suppose we had late goal in the first half and early goal in the second (45'+5' and 46) — my algorithm will pick second half goal as earlier. We need to somehow pass half (or part for extra-time) data to sort goal times. Fortunately, Clojure sorts collections of pairs well:

We need to calculate both half (part) and exact time of scoring a goal:
(defn part [goal]
(let [time (first goal)]
(cond
(<= time 45) 1
(<= time 90) 2
(<= time 105) 3
(<= time 120) 4))) ;; parts 3 and 4 are for extra-time
(defn parts [time-str]
(->>
(string/split time-str #"\+")
(map string/trim)
(map #(string/replace % #"'" ""))
(map #(Integer/parseInt %))))
(defn part-and-time [time-str]
(let [parts (parts time-str)]
[(part parts) (reduce + parts)]))
Now we can test improved sorting:

Seems to work! So let’s try to find a team that scored a first goal. My idea was to mix both :home and :away goal times in one collection:
([:home [1 38]] [:home [1 39]] [:away [1 28]])
and then sort by times:
([:away [1 28]] [:home [1 38]] [:home [1 39]])
to know the side that scored first goal (:away in this case).
(defn first-scored-side [match]
(let [goal-times
(concat
(team-goal-times (:home_team_events match) :home)
(team-goal-times (:away_team_events match) :away))]
(->> goal-times (sort-by second) first first)))
I use first to get the first pair from sorted collection and then first again to get the first element from the pair:

To create a list with goal times and side I used this function:
(defn team-goal-times [events side]
(->> events
(filter goal?)
(map :time)
(map part-and-time)
(map vector (repeat side))))
What’s happening in this last line? So, repeat returns an infinite lazy sequence with an element repeated and vector just creates an indexed collection from provided elements.

And map can also take two collections, applying provided function to pairs: <c1_first, c2_first>, <c1_second, c2_second>…

Which leads us easily to this:

Ok, now we are ready write this come-back? function now:
(defn winner-side [match]
(let [winner (:winner match)]
(cond
(= winner (:home_team_country match)) :home
(= winner (:away_team_country match)) :away)))
(defn come-back? [match]
(let [first-scored-side (first-scored-side match)
winner-side (winner-side match)]
(and (not (nil? winner-side))
(not= winner-side first-scored-side))))
Let’s see if it works, just filter the team’s data from the match to remove noise:
(defn teams [match] (select-keys match [:home_team_country :away_team_country :winner]))
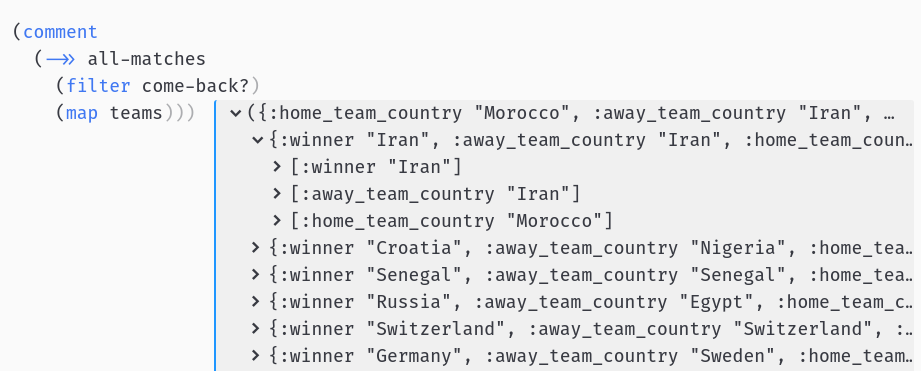
Ok, we got some results! But, hmm… Morocco — Iran?
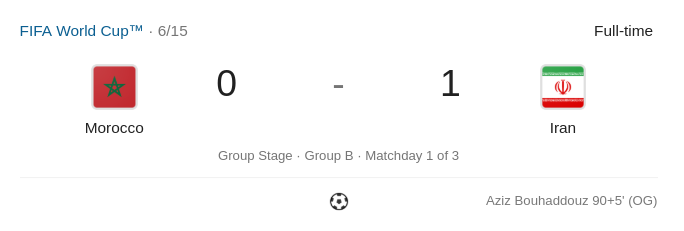
0:1 with last-minute own goal? This definitely doesn’t look like come-back…. Let’s look at this match events:
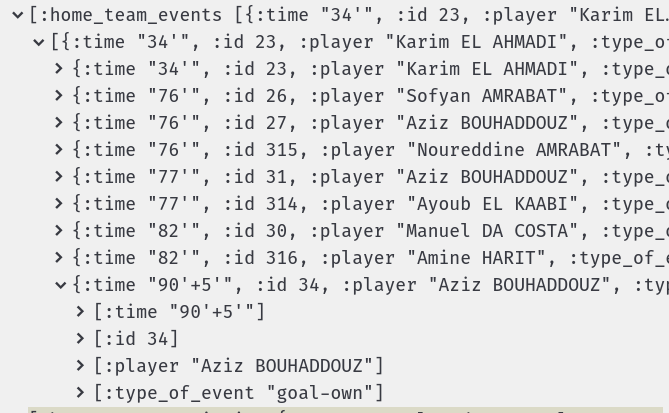
Ok, now I can see the problem. Own goals are contained in wrong side’s events! This goal should be in Iran’s events, otherwise our solution won’t work…
We can make a special case for own goals or just move own goals to correct side events. I decided to go with the second solution, knowing that Clojure is really good at transforming nested data structures e.g. with update and update-in functions:

So, update takes a map, a key and a function and applies to value under that key, leaving rest of the map untouched. update-in works the same, but you can pass a whole path to some nested element in your data structure.
Let’s use update to move all the own-goals from :home_team_events to :away_team_events and vice-versa:
(defn own-goal? [event]
(= "goal-own" (:type_of_event event)))
(defn own-goals [events]
(->> events (filter own-goal?)))
(defn remove-own-goals [events]
(remove own-goal? events))
(defn fix-match [match-to-fix]
(let [own-home-goals (own-goals (:home_team_events match-to-fix))
own-away-goals (own-goals (:away_team_events match-to-fix))]
(-> match-to-fix
(update :home_team_events remove-own-goals)
(update :away_team_events remove-own-goals)
(update :home_team_events concat own-away-goals)
(update :away_team_events concat own-home-goals))))
And finally let’s fix come-back? function:
(defn come-back? [match-to-fix]
(let [match (fix-match match-to-fix)
first-scored-side (first-scored-side match)
winner-side (winner-side match)]
(and (not (nil? winner-side))
(not= winner-side first-scored-side))))
Check the results again:
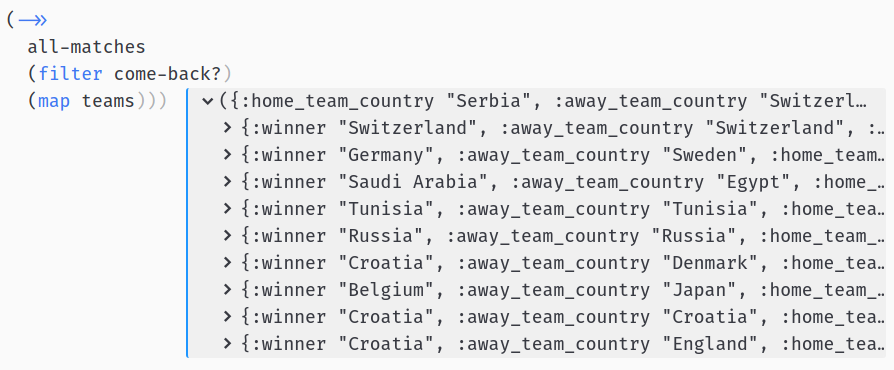
Yes, we have it! We found 9 such games, with overall leader Croatia coming back 3 times (2 by penalties).