Vavr is now a must-have for every modern Java 8+ project. It encourages writing code in a functional manner by providing a new persistent Collections API along with a set of new Functional Interfaces and monadic tools like Option, Try, Either, etc.
You can read more about it here.
Vavr’s Persistent Collections API
To provide useable immutable data structures, the whole Collections API needed to be redesigned from scratch.
The standard java.util.Collection interface contains methods that discourage immutability such as:
boolean add(E e); boolean remove(Object o); boolean addAll(Collection<? extends E> c); boolean removeAll(Collection<?> c);
One might think that the problem is that those methods allow modifications of the particular collection instance, but this is not entirely true – with immutable data structures, each mutating operation needs to derive a new collection from the existing one. Simply put, each of those methods should be able to return a new instance of the collection.
Here, the whole collections hierarchy is restricted to returning boolean or void from mutating methods – which makes them suitable only for mutable implementations.
Of course, immutable implementations of java.util.Collection exist, but above-mentioned methods are simply forbidden. That’s how it looks like in the com.google.common.collect.ImmutableList:
/**
* Guaranteed to throw an exception and leave the list unmodified.
*
* @throws UnsupportedOperationException always
* @deprecated Unsupported operation.
*/
@Deprecated
@Override
public final void add(int index, E element) {
throw new UnsupportedOperationException();
}
And this is far from perfect – even the simplest add() operation becomes a ceremony:
ImmutableList<Integer> original = ImmutableList.of(1); List<Integer> modified = new ImmutableList.Builder<Integer>() .addAll(original) .add(2) .build();
A major redesign made it possible to interact with immutable collections more naturally and add some new exciting features:
import io.vavr.collection.List; // ... List<Integer> original = List.of(1); List<Integer> modified = original.append(2); modified.dropWhile(i -> i < 42); modified.combinations(); modified.foldLeft(0 , Integer::sum)
Collecting Vavr’s Collections
One of the key features of the Java Stream API was the collect() API that made it possible to take elements from Stream and apply the provided strategy to them – in most cases that would be simply placing all elements in some collection.
Vavr’s collections have a method that provides the similar(but limited) functionality but it’s not being used often because almost all operations that were available only using Stream API, are available on the collection level in Vavr.
But… one of the method signatures of Vavr’s collect() is especially intriguing:
<R, A> R collect(java.util.stream.Collector<? super T, A, R> collector)
As you can see, Vavr’s collections are fully compatible with Stream API Collectors and we can use our favourite Collectors easily:
list.collect(Collectors.toList()); list.collect(Collectors.groupingBy(Integer::byteValue));
That might not be super useful for everyday use-cases because the most common operations are accessible without using Collectors but it’s comforting to know that Vavr’s functionality is a superset of Stream API’s (at least in terms of collect() semantics)
Collecting Everything
The interesting realization happens when we decide to investigate the type hierarchy in Vavr:
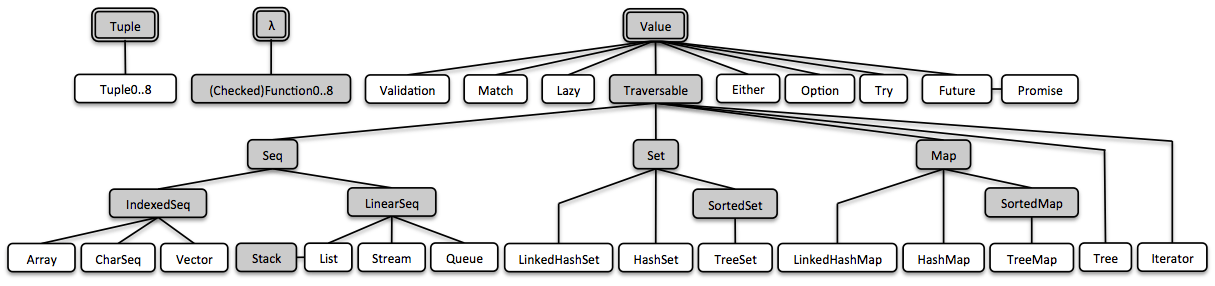
We can notice here that the Value resides on top collections hierarchy and this is where the collect() method mentioned above is defined.
If we look closer, it’s clear that classes like Option, Try, Either, Future, Lazy also implement the Value interface. The reasoning behind this is that they are all essentially containers for values – containers that can hold max up to one element.
This makes them compatible with Stream API Collectors, as well:
Option.of(42)
.collect(Collectors.toList());
Try.of(() -> URI.create("4comprehension.com"))
.collect(Collectors.partitioningBy(URI::isAbsolute));
Summary
The redesign of the Collections API allowed the introduction of cool new methods, as well as achieving full interoperability with Java Stream API Collectors – which can also be applied to Vavr’s functional control structures like Option, Try, Either, Future, or Lazy.
The examples above use:
<dependency>
<groupId>io.vavr</groupId>
<artifactId>vavr-test</artifactId>
<version>0.9.0</version>
</dependency>