During a last few evenings in my free time I’ve worked on mini-application called micro-burn. The idea of it appear from work with Agile Jira in our commercial project. This is a great tool for agile projects management. It has inline tasks edition, drag & drop board, reports and many more, but it also have a few drawbacks that turn down our team motivation.
Motivation From time to time our sprints scope is changing. It is not a big deal because we are trying to be agile :-) but Jira’s burndowchart in this situation draw a peek. Because in fact that
chart shows scope changes not a real burndown. It means, that chart cannot break down an x-axis if we really do more than we were planned – it always stop on at most zero. Also for better progress monitoring we’ve started to split our user stories to technical tasks and estimating them. Original burndowchart doesn’t show points from technical tasks. I can find motivation of this – user story almost finished isn’t finished at all until user can use it. But in the other hand, if we know which tasks is problematic we can do some teamwork to move it on. So I realize that it is a good opportunity to try some new approaches and tools.
Tools I’ve started with
lift framework. In the World of Single Page Applications, this framework has more than simple interface for serving REST services. It comes with awesome Comet support. Comet is a replacement for WebSockets that run on all browsers. It supports long polling and transparent fallback to short polling if limit of client connections exceed. In backend you can handle pushes in CometActor. For further reading take a look at Roundtrip promises But lift framework is also a kind of framework of frameworks. You can handle own abstraction of CometActors and push to client javascript that shorten up your way from server to client. So it was the trigger for author of lift-ng to make a lift with Angular integration that is build on top of lift. It provides AngularActors from which you can emit/broadcast events to scope of controller. NgModelBinders that synchronize your backend model with client scope in a few lines! I’ve used them to send project state (all sprints and thier details) to client and notify him about scrum board changes. My actor doing all of this hard work looks pretty small: Lift-ng also provides factories for creating of Angular services. Services could respond with futures that are transformed to Angular promises in-fly. This is all what was need to serve sprint history: And on the client side – use of service: In my opinion this two frameworks gives a huge boost in developing of web applications. You have the power of strongly typing with Scala, you can design your domain on Actors and all of this with simplicity of node.js – lack of json trasforming boilerplate and dynamic application reload.
DDD + Event Sourcing I’ve also tried a few fresh approaches to
DDD. I’ve organize domain objects in actors. There are SprintActors with encapsulate sprint aggregate root. Task changes are stored as events which are computed as a difference between two boards states. When it should be provided a history of sprint, next board states are computed from initial state and sequence of events. So I realize that the best way to keep this kind of event sourcing approach tested is to make random tests. This is a test doing random changes at board, calculating events and checking if initial state + events is equals to previously created state:
First look Screenshot of first version:
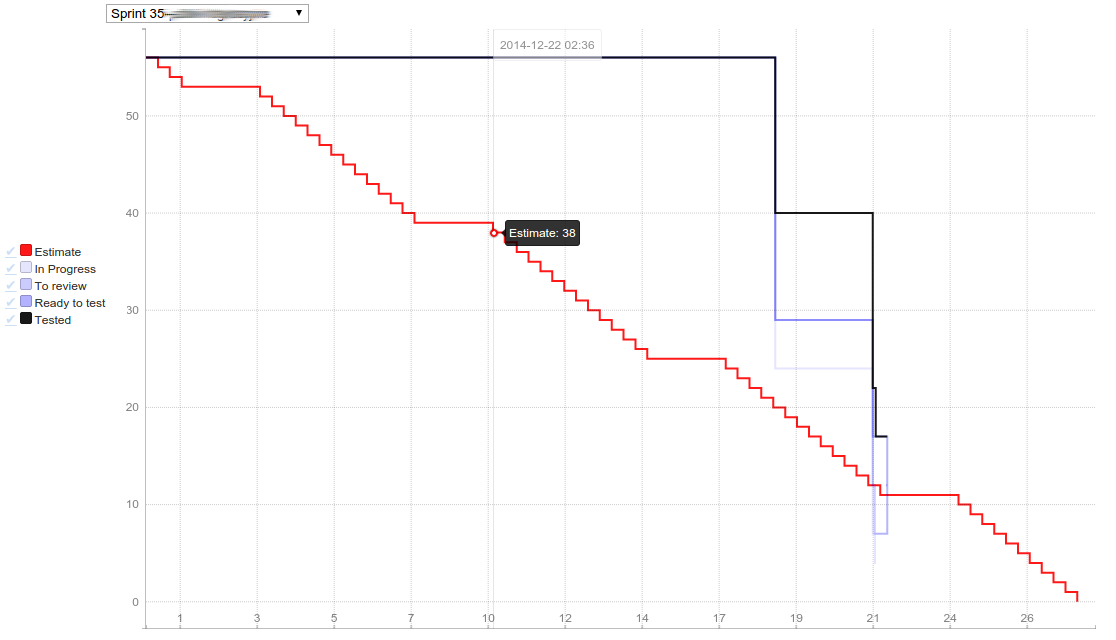
If you want to look at this closer, check the source code or download ready to run fatjar on