Every month we have a Friday Hackathon, where we can code or create anything we want. That’s for the purpose of evaluating new technologies, doing crazy stuff or just having fun.
Beneath that we develop our skills and gain new experience.
Today we have 5 teams, that are doing following projects in various technologies:
- Ping-pong scoring – we play ping pong a lot, so an app is a must! – Java (Dropwizard), Mongo
- TouK’s library – we have dozens of books but currently we have a chaos who lends what – Clojure
- ToukApi – access all internal data (about people, salaries, holidays, auth, projects people are in etc) through REST api – vert.x
- ID / Drivers license recognition on Mobile – just shoot a photo of an ID and have all data and photo in a few seconds – Kotlin, Android
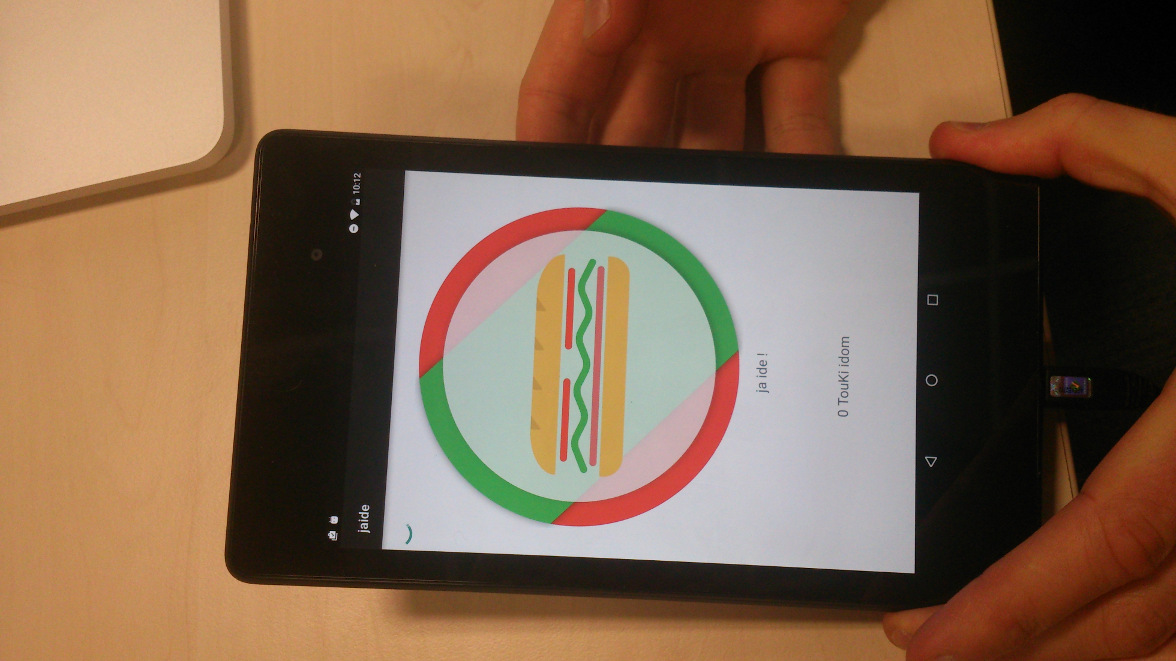
- jaIde – I’m going for a sandwich – you can inform other employees that you go for a morning sandwich – that means – Mr Sandwich has just arrived at the kitchen – it’s like a snowball, the more people go for a sandwich the more confident you can be that there are actually sandwiches waiting :) – Swift/Scala/Java
At 4:30 PM we have hackathon summary. Let’s see what projects we will manage to accomplish…