The last time we wanted to organize a Hackathon our plans were thwarted by “you know what”. This state of affairs has lasted so long that we just couldn’t stand it anymore and launched the next edition of The Hackathon – remotely. This time we had to cope with new conditions – not all together in an open space, but everyone at home. We launched the communicator with a separate room per each project and went into action.
Here we present a brief summary from each team.
RCB Alert
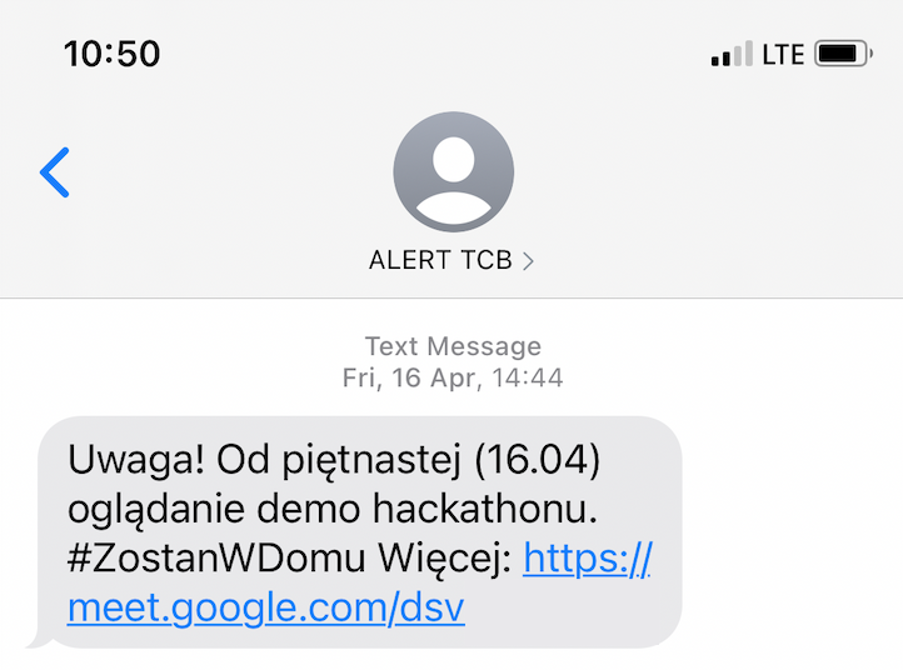 Every now and then we have a problem in our company – we need to inform everyone that the next day some loud redecorating is to take place or our air conditioning is to be cleaned – and we had better work remotely that day.
Every now and then we have a problem in our company – we need to inform everyone that the next day some loud redecorating is to take place or our air conditioning is to be cleaned – and we had better work remotely that day.
Unfortunately, sometimes our office managers gain this knowledge after our working hours, so there is no channel to notify everyone (hopefully – no one reads emails at home).
We found a solution to this problem during our last Hackathon.
We wrote a piece of software that orders an SMS to be sent to each person subscribed to TCB Alerts (it’s a pun on our government alerts – RCB).
This was the easy part – as we already had an SMS sending service.
However, we wanted this solution to be as easy as possible, so our office managers don’t have to open their laptops, connect to a VPN, search for special forms etc.
We decided to implement it as a hook to our communicator – RocketChat.
Now, when our office managers need to inform everyone in the evening, they need only to open the RocketChat app on their phone and type a message on a special channel – and that’s it!
We hope that this solution will help us to stay at home and work remotely during the days when it is inconvenient to work from the office.
TouK AboutMe
 Currently at TouK we have several selfcare services providing information about TouKs (people working or cooperating with TouK).
Currently at TouK we have several selfcare services providing information about TouKs (people working or cooperating with TouK).
The aim of our project was to join these services into one. Of course we know the rule that if you have three separate services then the worst approach is to add a new one. For this reason we enriched the most modern of them with new features such as TouK’s search, adding new information about people, teams information management and much more.
During the hackathon our team of four (+ the business owner) learnt a lot about frontend technologies such as CORS, MongoDB and LDAP.
We all hope that our work will prove to be useful for both current and future TouKs. Our team strove to provide a user experience so seamless that users would wonder at how easy selfcare management could be. We trust that with this hackathon we are a step closer to achieving that goal.
Business Config Manager
During our deployments of Nussknacker we often have the situation that the flow of development of scenarios was done by two teams. One of them is a team called “Configurators” – people who are close to business requirements but also with quite a high level of technical skills. Those people are responsible for the development of scenarios on the Nussknacker side. On the other hand, the second team is made up of Business members, those with lower technical skills but with a good knowledge of customer needs.
Configurators want to outsource some steps of development to business – so some changes can be made faster, without involving Configurators in the process. We found out that we should make a tool that can give Configurators the ability to create definitions of some configurations and after that, Business can fill in the values of those configurations. In the end, this configuration will be used in some steps of the scenario in Nussknacker.
After the deployment of the proof of concept, we realized that it is necessary to handle some important things:
- Both definitions of configurations and values should be versioned and have some audit information, such as the author and time of the change.
- Migrations of changes in definitions should be painless.
- We should support many types of properties: from raw strings to some date time pickers and so on.
- Configurations should have a lifecycle, so new ideas can be deployed on a lower environment and after some tests can be promoted to higher env.
After brainstorming before the Hackathon, we decided to use modern stack, but with some solid, battle-tested components:
We also designed the domain level of application.
On the first day of the Hackathon, we started with pair programming. We tried to go through all layers of the application to make sure that everyone in the team has a common vision of what the architecture will look like. After that we split the work into four separate parts:
- Management of definitions
- Management of values
- Nussknacker integration with Business Config Service
- Web application Finally, we integrated all the features together and completed the MVP step.
The project ended successfully. We proved that our design was correct, prepared a solid foundation for future development, and had a lot of fun designing the architecture and testing new tools.
Nussknacker Serverless
Most of you probably know Nussknacker – a powerful platform which allows non-technical users to author and deploy streaming scenarios on Apache Flink.
But Nussknacker Designer can also describe more business rules-oriented scenarios – used e.g. in recommendations or NBA domains. In this case, the scenario is deployed as a REST microservice. During the Hackathon we decided to make this setup more Kubernetes/Serverless-oriented. We decided that a Nussknacker scenario is a good candidate for K8 CRD and that KNative will provide us with a serverless deployment platform.
In two days we reached most of our goals:
- Nussknacker creating scenario ConfigMap during deployment (in the future it will be CRD)
- Custom Kubernetes operator/controller which transforms scenario ConfigMap into KNative service (scaling down to zero if needed :))
- Simple REST microservice image, which serves the scenario
- Everything deployed via Helm/GitlabCI to our DigitalOcean K8 cluster
We are also pretty excited about the next steps – scenario observability (metrics, statuses), CRDs and making our serving image serverless ready – by using GraalVM native images.
Hopefully, in the short to medium term, all of this will be accessible with our Nussknacker offering.
MusicBox
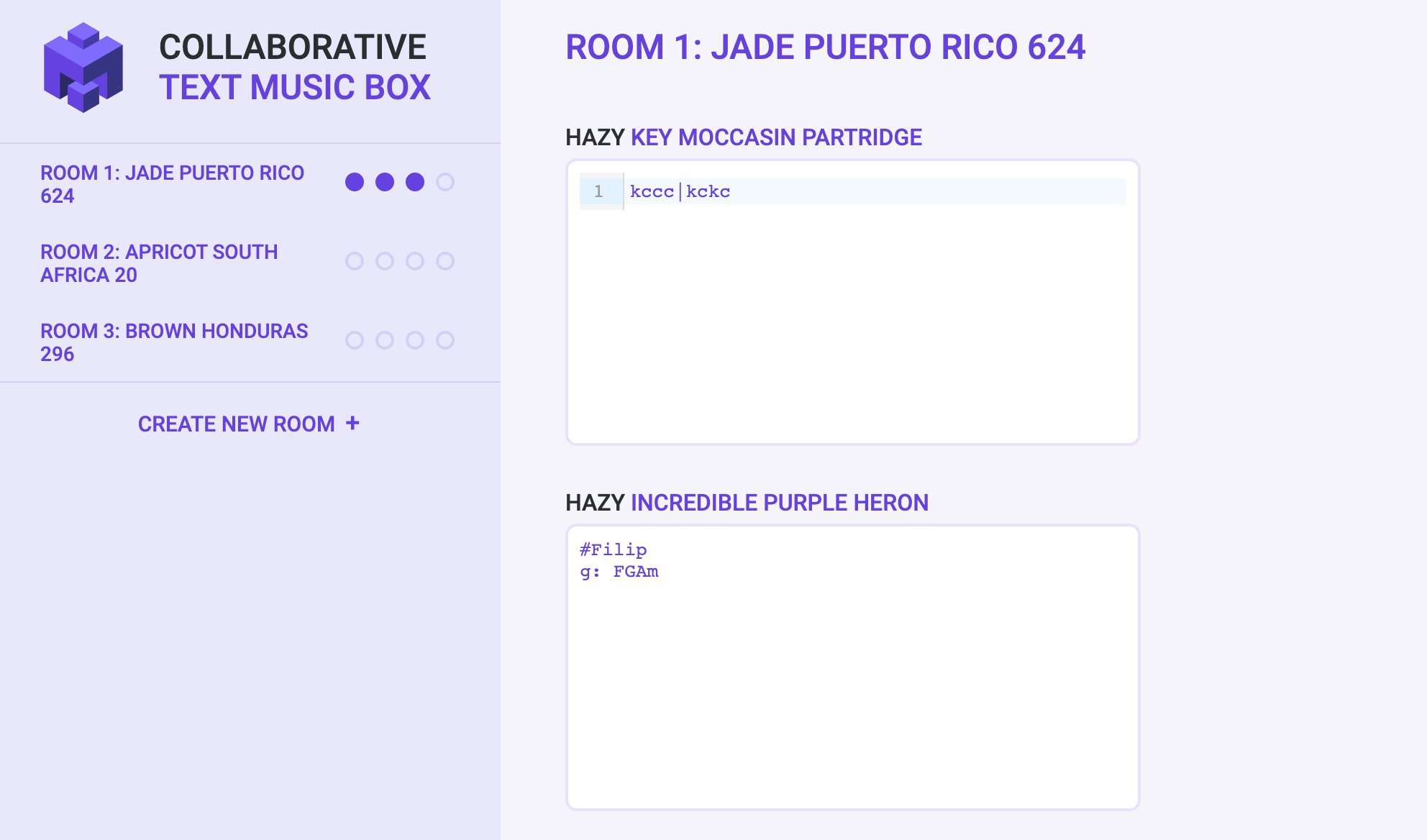 We have created a minimalistic web app for generating music in a loop based on text input.
We have created a minimalistic web app for generating music in a loop based on text input.
The idea is to make writing music as easy as possible. E.g. |k h s h | is the most basic percussive beat, while |Am|C| gives a basic chord progression. Furthermore, there’s a collaborative mode (think jam sessions ;).
Frontend:
- TypeScript
- SnowPack
- WebSocket
- Tone.js (music generation)
Backend:
Summary
In our opinion, The Hackathon was successful and fulfilled its task – that is, it allowed us to take a short break from our more important work and experiment with various fun technologies in good company. The fact that during the Hackathon team members were in a voice chat with each other certainly played a big role, which to some extent allowed us to build an atmosphere of cooperation in the fight against challenges.
We are already looking forward to the next hackathon – hopefully, this time on site.
If you want, here you can see what we did during the previous edition.