Actuator Metrics
As reported in Michał Bobowski post, we heavily use Spring Boot Actuator metrics system based on Micrometer. It provides a set of practical metrics regarding JVM stats like CPU or memory utilization. Our applications have to meet the most sophisticated needs of our clients thus we try to take advantage of http.server.request endpoint.
Introduction
By default, Spring Boot Actuator gathers endpoint statistics for all classes annotated with @RestController. It registers a WebMvcMetricsFilter bean, which is responsible for timing a request. A special TimingContext attribute is attached to the request so that Spring Boot knows when the request started.
Actuator metrics model
When you call http://localhost:8080/actuator/metrics/http.server.request endpoint you will get something similar to this:
{
"name": "http.server.requests",
"description": null,
"baseUnit": "milliseconds",
"measurements": [
{
"statistic": "COUNT",
"value": 12
},
{
"statistic": "TOTAL_TIME",
"value": 21487.256644
},
{
"statistic": "MAX",
"value": 2731.787888
}
],
"availableTags": [
{
"tag": "exception",
"values": [
"None",
"RuntimeException"
]
},
{
"tag": "method",
"values": [
"GET"
]
},
{
"tag": "uri",
"values": [
"/example/success"
]
},
{
"tag": "outcome",
"values": [
"SERVER_ERROR",
"SUCCESS"
]
},
{
"tag": "status",
"values": [
"500",
"200"
]
}
]
}
You will surely see the measurements section. It provides types and values of statistics recorded at a certain point in time. Types of statistics are ones described in Statistics enum.
Another one is the availableTags section, which contains a set of default tags distinguishing each metric by URI, status, or method. You can easily put your tags there like a host or container. If you want to check metric for a particular tag, Actuator lets you do this by using tag query http://localhost:8080/actuator/metrics/http.server.request?tag=status:200
Metric system model
However, each monitoring system has its own metrics model and therefore uses different names for the same things. In our case, we use Influx Registry.
Let’s look into InfluxMeterRegistry class implementation.
private Stream writeTimer(Timer timer) {
final Stream fields = Stream.of(
new Field("sum", timer.totalTime(getBaseTimeUnit())),
new Field("count", timer.count()),
new Field("mean", timer.mean(getBaseTimeUnit())),
new Field("upper", timer.max(getBaseTimeUnit()))
);
return Stream.of(influxLineProtocol(timer.getId(), "histogram", fields));
}
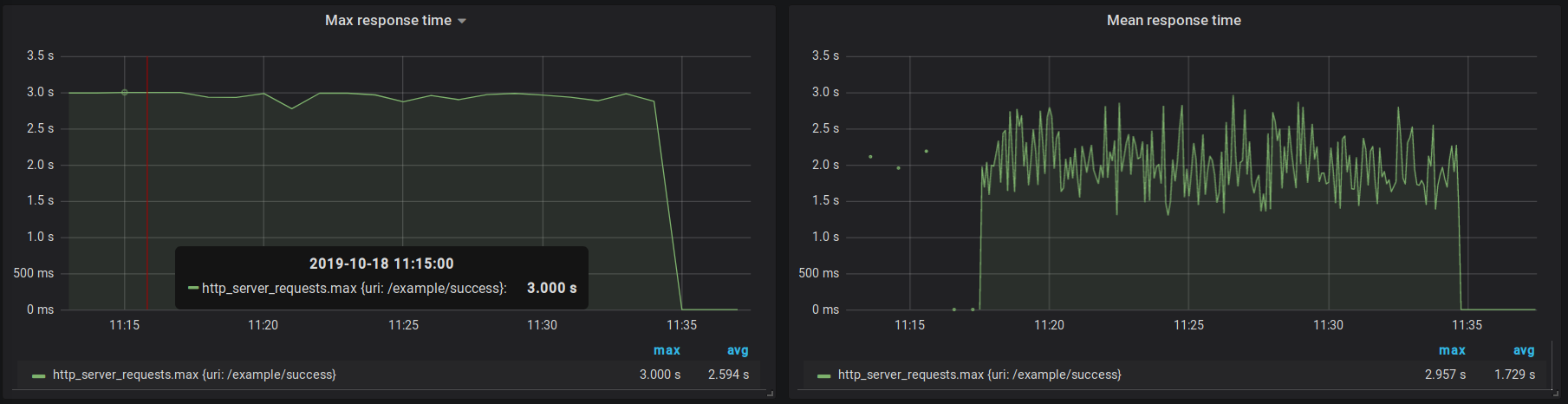
We see which field in influx corresponds to actuators measurement. Moreover, our registry equips us with an additional mean field, which is basically TOTAL_TIME divided by COUNT. Therefore we don’t need to calculate it manually inside our monitoring system.
Summary
(1) Be aware that the Actuator metric model directly corresponds to Micrometer model
(2) When it comes to timing requests carefully choose the step in which metrics are exported
(3) Do not mix composing metric values with aggregations, selectors, and transformations, e.g. mean(mean)
