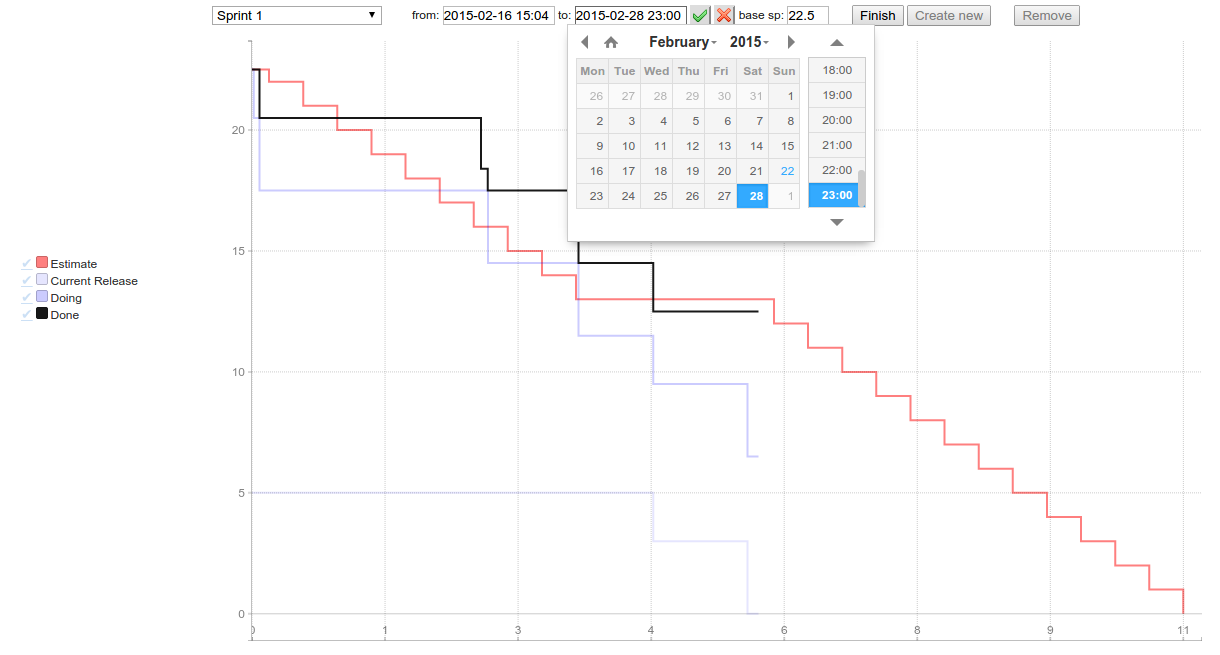
After a few long evenings I’ve finally integrated micro-burn with Trello. All you need to run it for your Trello board is to write short configuration and run fat jar. It renders burndown chart visualising progress of cards on your board.
You can specify story points adding them in curly braces inside card title, use Scrum for Trello browser extension or define default story points number for user stories. Completed checklist items are treated as a part of work done inside card. You can manage sprints on your own: creating new, specifying start/end/name, finishing or turn on full automatic mode: sprints will be created periodically.
Sprint management in usage: