Sputnik runs Checkstyle, PMD and FindBugs for your Gerrit patchsets
I am happy to announce a first release of Sputnik! It is a static code analyzer that runs Checkstyle, PMD and FindBugs for your Gerrit patchsets. Its main advantage over my previous project Sonar Gerrit plugin is that Sputnik is a small, lightweight and standalone Java application. You don’t need any other software to run it. It bundles Checkstyle, PMD and FindBugs jars within distribution zip.
Workflow
Sputnik is intended to use with Gerrit and Continous Integration server, i. e. Jenkins. It works like this:
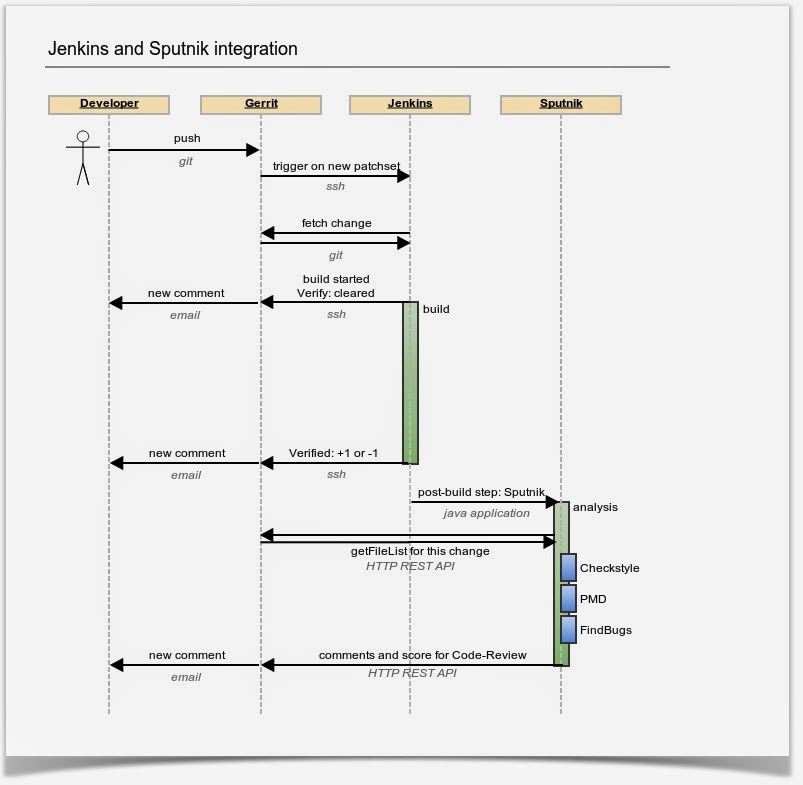
Your CI server is updated by ssh that a new patch is submitted to Gerrit. CI fetches this patch and builds a while project. After a build, CI server reports its result to Gerrit. It’s time for Sputnik now.
Sputnik runs regardless of build result (you can change that in your CI configuration). Sputnik fetches patchset’s file list from Gerrit over HTTP REST API. Then it runs an analysis only on these files! Even if your project is huge, analysis on several files takes only seconds. Sputnik collects comments from all three analysers: Checkstyle, PMD and FindBugs. It sends back all comments to Gerrit via HTTP REST API back. It’s very simple and very fast!
Installation and configuration
First, you need to build https://github.com/TouK/sputnik master or download distribution zip from here: sputnik-1.0.zip. Go to you CI server and extract it to a directory of your choice. Remember that a user you run CI builds needs to have an access rights to this directory (in my case it’s simply a jenkins user). Then you need to prepare your configuration file and write this file to the same directory as unzipped distribution. It is a simple Java properties file, which is pretty self-explanatory. Here is an example:
gerrit.host=gerrit.yourcompany.com gerrit.port=8080 gerrit.username=sputnik gerrit.password=Pa$$wo4d checkstyle.enabled=true checkstyle.configurationFile=/opt/jenkins/sputnik/checkstyle.xml checkstyle.propertiesFile= pmd.enabled=true pmd.ruleSets=/opt/jenkins/sputnik/pmd.xml findbugs.enabled=true findbugs.includeFilter=/opt/jenkins/sputnik/findbugs.xml findbugs.excludeFilter=
Now you need to configure you CI server to actually run Sputnik after a build. It is very simple for Jenkins, just add a Post-Build Step. You can adjust if Sputnik runs only on successful build or for every build – use radio buttons for this:
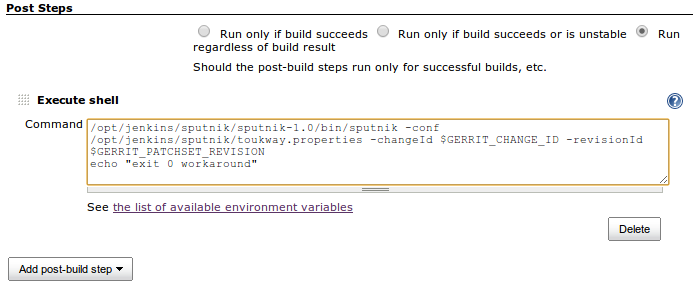
Last line with exit 0 is a workaround for a clean exit, even if Sputnik fails for some reason. Exit 0 guarantees you that result of this step doesn’t affect overall build result.
Summary
This is an example screenshot of Sputnik’s comments:

Sputnik always reports +1 as a result. It can be lacking in some network and authorisation configuration. But it’s open source so please submit issues and patches to its github page: https://github.com/TouK/sputnik.
Your feedback and pull requests are heartly welcome!