I was recently puzzled by strange behaviour of Grails application with web service interface. It resulted with rounding currency amount values when I sent request from my browser but it worked perfectly if another client application sent same request. After investigation it turned out that the HTTP requests were not exactly identical. The browser request contained header entry with Polish locale pl-PL for which coma is a decimal separator.
Request http://localhost:8080/helloworld/amount/displayAmount?amount=12.22
Header
Accept-Language: pl-PL,pl;q=0.8,en-US;q=0.6,en;q=0.4
In order to reproduce this behaviour I created a simple Grails 2.1 HelloWorld app.
AccountController.groovy
package helloworld
class AmountController {
def displayAmount(PaymentData paymentData) {
render "Hello, this is your amount: " + paymentData.amount.toString()
}
}
PaymentData.groovy:
package helloworld
import grails.validation.Validateable
@Validateable
class PaymentData {
BigDecimal amount
static constraints = {
amount(nullable: false, min: BigDecimal.ZERO, scale: 2)
}
}
Starting this app we can observe rounding of cents in amount to 00 when sending request with dot in amount (http://localhost:8080/helloworld/amount/displayAmount?amount=12.22)
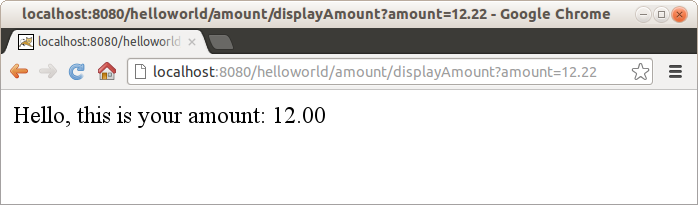
Whereas for amount with coma it gives a result with valid cent part (http://localhost:8080/helloworld/amount/displayAmount?amount=12,22)

Same behaviour might be expected in case of other locales that use coma as decimal separator, e.g. de_DE. Very not an obvious feature.