Initial release
I am happy to announce a first release of my Sonar Gerrit plugin. This plugin reports Sonar violations on your patchsets to your Gerrit server. Sonar analyses full project, but only files included in patchset are commented on Gerrit. Please forward to project page for installation instructions.
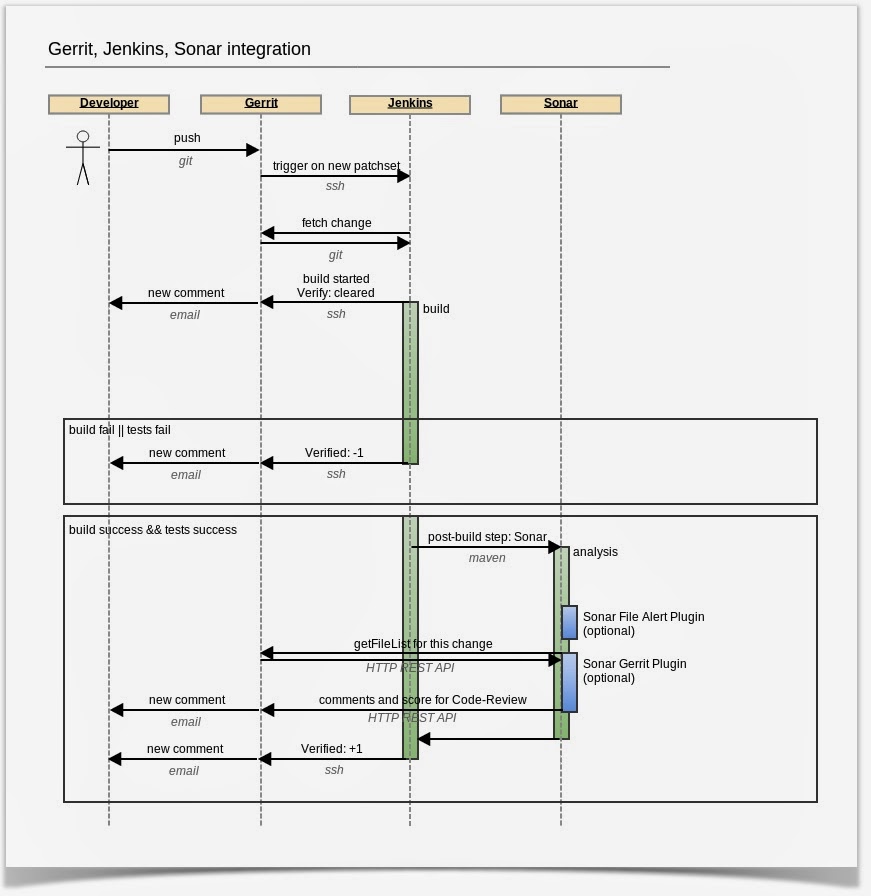
This plugin is intended to use with Gerrit Trigger plugin for Jenkins CI server. Together they provide a great tool for automatic static code analysis.
How does it work?
At the moment you push a patchset to Gerrit, Jenkins is notified with a ssh event. It fetches a code with a patchset and it builds your changes. It quits when build or tests fail.
But if it succeeds, Sonar analase your project in a post-build action. This is a place where my Sonar Gerrit plugin shines. It asks Gerrit for changed files before analysis and after Sonar analysis is finished, plugin reports comments on these files as a Gerrit reviewer. Currently plugin always reports +1 for Code Review, as it’s still in development. However, you should always treat these comments as hints to improve, not as direct errors.
Extras
I’ve released also a second plugin: Sonar File Alerts plugin. This plugin raises alerts on file level in Sonar. It extends default behaviour, which raises alerts only at root project level. It is useful when you create alert rules in Sonar like "Code Coverage < 60". Each file is checked against this rule!
If you use Sonar File Alerts plugin and an alert will be generated on some file, then a comment will be published on this file on Gerrit.
Feedback
Please provide a feedback on these plugins. Feel free to submit issues on github or comment. It’s still an early stage so your input is very welcome!