… czyli decyzje, o których nie wiesz, że będziesz musiał je podjąć, na podstawie dużej ilości danych, o których nie wiesz, że masz je zbierać.
Poniższy artykuł odpowiada mniej więcej prezentacji jaką miałem przyjemność przedstawić na konferencji “Business Intelligence w instytucjach finansowych”. W związku z tym mogą w nim występować pewne problemy wynikające z trudności przełożenia tekstu mówionego na pisany.
Jednak w wielu przypadkach sami zawężamy swoje możliwości. Dużo wcześniej od zebrania danych czynimy co do nich zaawansowane założenia. Dopiero z tak zebranych (według uprzednich założeń) danych staramy się wyciągać informacje o obecnym stanie przedsiębiorstwa. Tej niedogodności można uniknąć przez zwinne podejście do Business Intelligence. 

Według tego modelu sytuacje dzielimy na proste, trudne, złożone i chaotyczne. Każda sytuacja ma inną charakterystykę i w każdej nasze postępowanie powinno być inne.
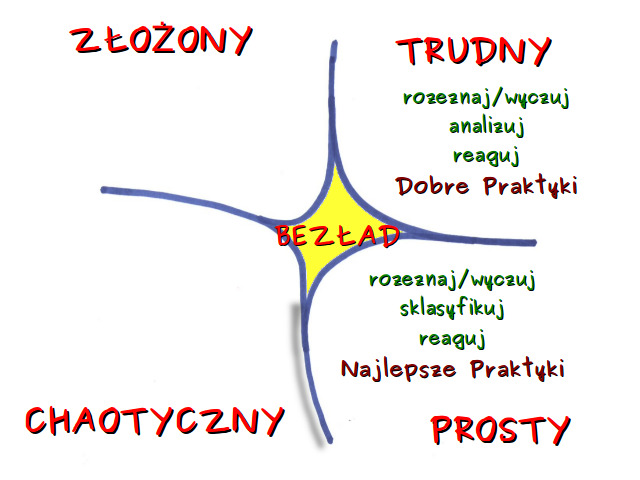 Sytuacje proste i trudne należą do dziedziny uporządkowanej, co oznacza, że istnieje ścisła zależność przyczynowo skutkowa, którą można przewidzieć. W przypadkach prostych taka zależność jest dostrzegalna dla każdej rozsądnej osoby, a nasze postępowanie sprowadza się do rozeznania, sklasyfikowania okoliczności i podjęcia właściwej decyzji. Ponieważ mamy pełną wiedzę na temat sytuacji po prostu bazujemy na najlepszych praktykach, działamy według reguł. Przykład? No income, no job or assets – wniosek – nie udzielamy kredytu. Oczywiście w tym miejscu, ze względu na nikłą wiedzę z zakresu finansów mogę popełniać błąd traktując jako prostą sytuację w rzeczywistości złożoną.
Sytuacje proste i trudne należą do dziedziny uporządkowanej, co oznacza, że istnieje ścisła zależność przyczynowo skutkowa, którą można przewidzieć. W przypadkach prostych taka zależność jest dostrzegalna dla każdej rozsądnej osoby, a nasze postępowanie sprowadza się do rozeznania, sklasyfikowania okoliczności i podjęcia właściwej decyzji. Ponieważ mamy pełną wiedzę na temat sytuacji po prostu bazujemy na najlepszych praktykach, działamy według reguł. Przykład? No income, no job or assets – wniosek – nie udzielamy kredytu. Oczywiście w tym miejscu, ze względu na nikłą wiedzę z zakresu finansów mogę popełniać błąd traktując jako prostą sytuację w rzeczywistości złożoną.
Sytuację trudną (skomplikowaną) od prostej odróżnia to, że o ile wiemy, że istnieje zależność przyczynowo-skutkowa, to może być ona niedostrzegalna na pierwszy rzut oka. Po rozeznaniu jesteśmy jednak pewni, że wykonując analizę jesteśmy w stanie tę zależność odkryć i na tej podstawie podjąć decyzję. Autor modelu przywołuje tutaj przykład zepsutego samochodu. Jego naprawa wymaga od nas, a w zasadzie od mechnika, czyli eksperta w dziedzinie, zbadania sprawy. Bez wykonania analizy nie możemy powiedzieć, co należy zrobić, by samochód naprawić. Jest też tak, że do właściwej diagnozy każdy mechnik może dojść, wykonując inne czynności (czy choćby w innej kolejności). Mamy więc wiele dobrych praktych i nie można powiedzieć, że któraś z nich jest lepsza.
Przyjmując, że Business Intelligence to wspracie dla podejmowania decyzji biznesowych, sytuacje określane jako trudne (skomplikowane) to doskonałe miejsce dla tradycyjnych systemów BI. Przypomnijmy, co się mniej więcej na nie składa.
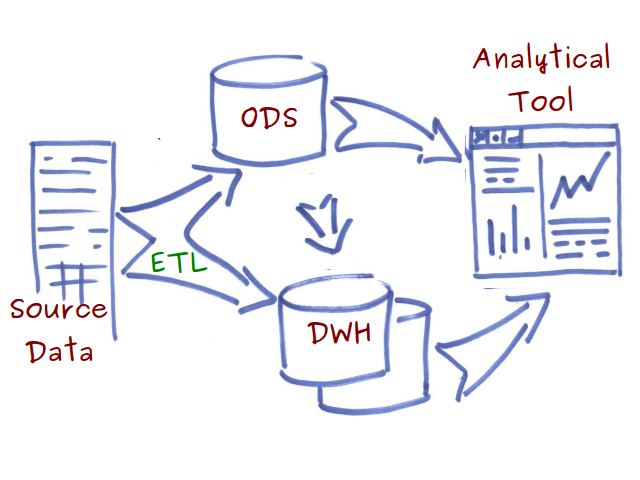 Dane żródłowe czy to z dziedzinowych baz danych czy choćby z plików w procesach ETL (extract-transform-load) trafiają do operacyjnego składu danych (Operational Data Store), gdzie są integrowane i porządkowane tematycznie (subject-oriented), bądź bezpośrednio do hurtowni danych (Data WareHouse), gdzie ich struktura jest optymalizowana pod kątem późniejszego przeszukiwania. Z tak przygotowanych danych korzystają narzędzia analityczne. Budowanie rozwiązania według takiej architektury jest oczywiście dobrą praktyką. Ma jednak pewne ułomności.
Dane żródłowe czy to z dziedzinowych baz danych czy choćby z plików w procesach ETL (extract-transform-load) trafiają do operacyjnego składu danych (Operational Data Store), gdzie są integrowane i porządkowane tematycznie (subject-oriented), bądź bezpośrednio do hurtowni danych (Data WareHouse), gdzie ich struktura jest optymalizowana pod kątem późniejszego przeszukiwania. Z tak przygotowanych danych korzystają narzędzia analityczne. Budowanie rozwiązania według takiej architektury jest oczywiście dobrą praktyką. Ma jednak pewne ułomności.
Jak sama nazwa wskazuje w procesie ETL wybieramy jedynie pewne dane z systemów źródłowych a następnie je przekształcamy. Zakładamy pewną interpretację danych przed ich zebraniem. Tracimy w ten sposób szczegóły, i jeżeli hurtownia danych jest jedynym miejscem przechowywania informacji historycznych, nie ma możliwości ich odzyskania.
Na diagramie powyżej hurtownia danych oznaczona została podwójnym symbolem. Ma to obrazować większą ilość danych, która jest w nich przechowywana. Jednakże klasyczne hurtownie danych z trudem skalują się wszerz (scale out) tzn. na wiele fizycznych komputerów. Ogólnie w przypadku relacyjnych baz danych preferowane jest skalowanie wzwyż (scale up), czyli przez zwiększanie możliwości jednej maszyny. Mimo ciągłego zwiększania możliwości technicznych sprzętu komputerowego, jest to ograniczanie zakresu przechowywanych danych.
 W ogromnej większości przypadków pod hasłem hurtownia czy ODS danych kryje się rozwiązanie oparte na relacyjnej bazie danych. Model relacyjny wymaga, aby przed zebraniem danych nadać, narzucić na te dane korelacje.
W ogromnej większości przypadków pod hasłem hurtownia czy ODS danych kryje się rozwiązanie oparte na relacyjnej bazie danych. Model relacyjny wymaga, aby przed zebraniem danych nadać, narzucić na te dane korelacje. 
 Ponadto tworzenie hurtowni w oparciu o relacyjny model danych ogranicza wydajność w niektórych klasach problemów jak przeszukiwanie danych tekstowych czy przechodzenie grafów (Jakiej grupie klientów promocyjnie sprzedać produkt, by “moda” na niego najszybciej się rozprzestrzeniła?).
Ponadto tworzenie hurtowni w oparciu o relacyjny model danych ogranicza wydajność w niektórych klasach problemów jak przeszukiwanie danych tekstowych czy przechodzenie grafów (Jakiej grupie klientów promocyjnie sprzedać produkt, by “moda” na niego najszybciej się rozprzestrzeniła?).
Zastanówmy się jak w czasie wygląda podejmowanie decyzji w oparciu o analizę z takiego tradycyjnego systemu BI. Większość dostawców takich rozwiązań chwali się szybką dostępnością analiz od chwili zebrania danych. Jest to prawda i wielka zaleta tych rozwiązań. Pomija się jednak dwa istotne aspekty. Jeden – wspomniany wyżej – że całe “czyszczenie” i porządkowanie danych, które ma taki pozytywny wpływ na wydajność takiego systemu, sprawia, że nie możemy danych tych nazwać pełnymi. 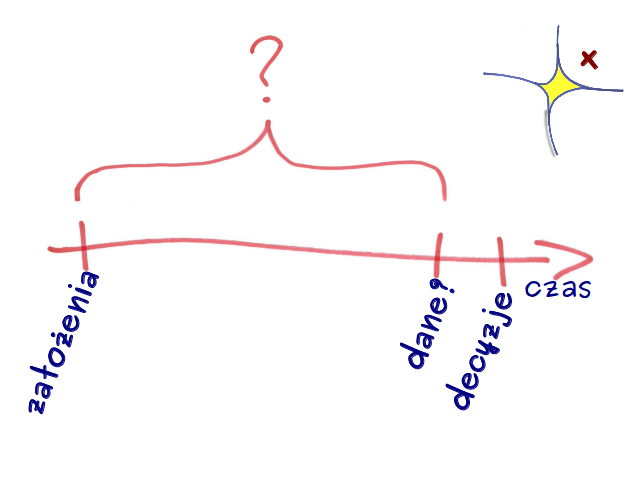 Drugi problem to czas jaki mija od momentu poczynienia założeń (jakie dane zbieramy, co z nich wybieramy, jak je porządkujemy) do chwili, kiedy zaczynamy gromadzić dane (w hurtowni), czyli de facto czas wdrożenia tradycyjnego rozwiązania BI. W 2010 roku firma Pentaho ogłosiła konkurs na swojej witrynie internetowej na najlepszą odpowiedź na pytanie “Co to jest Zwinne BI?”. Już po zakończeniu konkursu jeden z pracowników tej firmy napisał na swoim blogu, że ma spóźnione zgłoszenie do konkursu. Stwierdził, że Agile BI, to wszystko, co jest nie tak w informacji (rzeczywistej informacji prasowej) “Firma Bxxx Hxxx wdrożyła system BxxxOxxx firmy SXX w mniej niż rok“. Upraszczając kilkumiesięczny okres pomiędzy poczynieniem założeń a rozpoczęciem zbierania danych to sukces. Prawdopodobnie jest to sukces. Jednakże mamy w takim wypadku bardzo dobre rozwiązanie, ale wdrażające co najwyżej uprzednio znane dobre praktyki, czyli właściwe do zastosowania w sytuacjach trudnych (skomplikowanych).
Drugi problem to czas jaki mija od momentu poczynienia założeń (jakie dane zbieramy, co z nich wybieramy, jak je porządkujemy) do chwili, kiedy zaczynamy gromadzić dane (w hurtowni), czyli de facto czas wdrożenia tradycyjnego rozwiązania BI. W 2010 roku firma Pentaho ogłosiła konkurs na swojej witrynie internetowej na najlepszą odpowiedź na pytanie “Co to jest Zwinne BI?”. Już po zakończeniu konkursu jeden z pracowników tej firmy napisał na swoim blogu, że ma spóźnione zgłoszenie do konkursu. Stwierdził, że Agile BI, to wszystko, co jest nie tak w informacji (rzeczywistej informacji prasowej) “Firma Bxxx Hxxx wdrożyła system BxxxOxxx firmy SXX w mniej niż rok“. Upraszczając kilkumiesięczny okres pomiędzy poczynieniem założeń a rozpoczęciem zbierania danych to sukces. Prawdopodobnie jest to sukces. Jednakże mamy w takim wypadku bardzo dobre rozwiązanie, ale wdrażające co najwyżej uprzednio znane dobre praktyki, czyli właściwe do zastosowania w sytuacjach trudnych (skomplikowanych).
Jednak nie wszystkie sytuacje są proste bądź trudne. Dochodzimy do kolejnego kontekstu, w których przychodzi nam podejmować decyzje, który model Cynefin określa jako złożony. 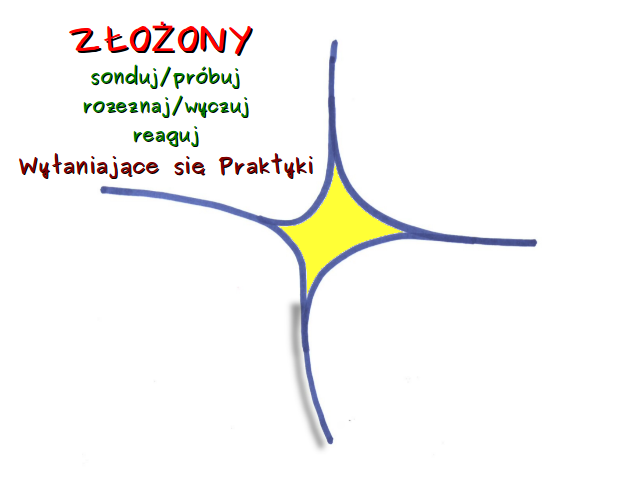 Tutaj zależności przyczynowo skutkowej nie można przewidzieć. Może być dostrzeżona jedynie patrząc wstecz, z czego jednak nie wynika, że ten sam ciąg zdarzeń w przyszłości doprowadzi do takiego samego efektu. Wśród studentów informatyki jednym z popularniejszych tematów prac magisterskich w pewnym czasie było (wciąż jest?) stworzenie oprogramowania, które na podstawie informacji giełdowych z przeszłości pozwoliłoby na przewidywanie kształtowania kursów spółek. Jak łatwo się domyślić, żaden z tych projektów nie doprowadził autora do wielkiego majątku.
Tutaj zależności przyczynowo skutkowej nie można przewidzieć. Może być dostrzeżona jedynie patrząc wstecz, z czego jednak nie wynika, że ten sam ciąg zdarzeń w przyszłości doprowadzi do takiego samego efektu. Wśród studentów informatyki jednym z popularniejszych tematów prac magisterskich w pewnym czasie było (wciąż jest?) stworzenie oprogramowania, które na podstawie informacji giełdowych z przeszłości pozwoliłoby na przewidywanie kształtowania kursów spółek. Jak łatwo się domyślić, żaden z tych projektów nie doprowadził autora do wielkiego majątku.
W sytuacjach złożonych tryb postępowania opiera się na eksperymentowaniu. Próbujemy pewne rozwiązania, sondujemy możliwości. Dopiero potem rozeznajemy problem i odpowiednio reagujemy.
Wspomniane rynki finasowe są dobrym przykładem systemu złożonego. Patrząc wstecz możemy mówić o przyczynach i skutkach. Możemy dostrzegać pewne wzorce zachowań, które mogą wyłonić się pewne w miarę skuteczne praktyki. Z całą pewnością nie istnieje jednak zbiór dobrych praktyk, o którym wiemy, że doprowadzi nas do sukcesu. Tradycyjne rozwiązania BI dające nam pewien zestaw narzędzi nie są w tym przypadku bardzo pomocne.
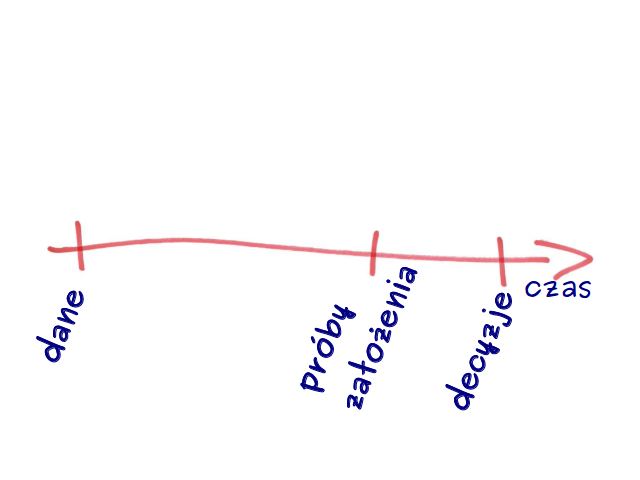 Wracając do osi czasu, aby eksperymentować potrzebujemy takiego rozwiązania, które pozwoli zbierać maksymalnie dużo danych bez uprzednich założeń do nich. Mając te dane możemy czynić założenia do analiz a nawet próbując w krótkim okresie, jak eksperymentalne zmiany (np. oferty) wpływają na te dane. Dopiero to pozwala na podjęcie właściwych decyzji.
Wracając do osi czasu, aby eksperymentować potrzebujemy takiego rozwiązania, które pozwoli zbierać maksymalnie dużo danych bez uprzednich założeń do nich. Mając te dane możemy czynić założenia do analiz a nawet próbując w krótkim okresie, jak eksperymentalne zmiany (np. oferty) wpływają na te dane. Dopiero to pozwala na podjęcie właściwych decyzji. 

Można zastanawiać się jakiego rodzaju dane w instytucjach finansowych mogłyby zasługiwać na miano big data. Z pewnością kandydatem sa płatności kartowe czy przelewy. Zawierają one więcej informacji niż kwota.  To miejsce do dyskusji ze specjalistami od marketingu w tych instytucjach. Można zadać pytanie, czy przykładowo analitycy w banku mają świadomość popularności poszczególnych elementów serwisu internetowego i czy przekłada się to na indywidualnych klientów oraz kierowane do nich oferty. Co ciekawe działy IT mają wszystkie dane, by takie informacje przedstawić.
To miejsce do dyskusji ze specjalistami od marketingu w tych instytucjach. Można zadać pytanie, czy przykładowo analitycy w banku mają świadomość popularności poszczególnych elementów serwisu internetowego i czy przekłada się to na indywidualnych klientów oraz kierowane do nich oferty. Co ciekawe działy IT mają wszystkie dane, by takie informacje przedstawić. 
 Za tymi przykładami firm stoi określona technologia. Ze względu na przedstawione wcześniej ułomności nie jest ona oparta na modelu relacyjnym. Wykorzystane jest rozproszone przetwarzanie danych. Dane nie są przechowywane w jednej dużej bazie danych, która zakłada podział danych na kolumny i więzy integralności między nimi. W celu wydobycia informacji nie korzysta się też z zapytań SQL. Zamiast tego tworzy się implementacje algorytmów pozwalających na przetwarzanie danych na wielu komputerach w klastrze wykorzystując technologię MapReduce. Każda z maszyn w klastrze operuje na podzbiorze danych. Dystrybucję danych (faza map) i zebranie danych (faza reduce) zapewnia technologia. Wszystkie wspomniane firmy korzystają z open source-owej implementacji – Apache Hadoop.
Za tymi przykładami firm stoi określona technologia. Ze względu na przedstawione wcześniej ułomności nie jest ona oparta na modelu relacyjnym. Wykorzystane jest rozproszone przetwarzanie danych. Dane nie są przechowywane w jednej dużej bazie danych, która zakłada podział danych na kolumny i więzy integralności między nimi. W celu wydobycia informacji nie korzysta się też z zapytań SQL. Zamiast tego tworzy się implementacje algorytmów pozwalających na przetwarzanie danych na wielu komputerach w klastrze wykorzystując technologię MapReduce. Każda z maszyn w klastrze operuje na podzbiorze danych. Dystrybucję danych (faza map) i zebranie danych (faza reduce) zapewnia technologia. Wszystkie wspomniane firmy korzystają z open source-owej implementacji – Apache Hadoop.
 TouK ma wiedzę i doświadczenie w wykorzystaniu tego produktu. Realizujemy w oparciu o niego prace dla jednego z operatorów telefonii komórkowej. Wymogiem ustawowym operatorzy są zobligowani do gromadzenia danych na temat aktywności użytkowników sieci. Dane te pierwotnie przeznaczone na potrzeby organów bezpieczeństwa niosą za sobą również informacje biznesowe. W ramach projektu pewną klasę takich informacji gromadzimy w klastrze, na którym działa oprogramowanie Apache Hadoop, i udostępniamy do narzędzia analitycznego. Już 4 maszyny zapewniają wydajność rozwiązania identyczną jak w przypadku hurtowni danych działającej na jednej maszynie dwukrotnie droższej od kosztu calego klastra (nie licząc kosztu licencji relacyjnej bazy danych).
TouK ma wiedzę i doświadczenie w wykorzystaniu tego produktu. Realizujemy w oparciu o niego prace dla jednego z operatorów telefonii komórkowej. Wymogiem ustawowym operatorzy są zobligowani do gromadzenia danych na temat aktywności użytkowników sieci. Dane te pierwotnie przeznaczone na potrzeby organów bezpieczeństwa niosą za sobą również informacje biznesowe. W ramach projektu pewną klasę takich informacji gromadzimy w klastrze, na którym działa oprogramowanie Apache Hadoop, i udostępniamy do narzędzia analitycznego. Już 4 maszyny zapewniają wydajność rozwiązania identyczną jak w przypadku hurtowni danych działającej na jednej maszynie dwukrotnie droższej od kosztu calego klastra (nie licząc kosztu licencji relacyjnej bazy danych).
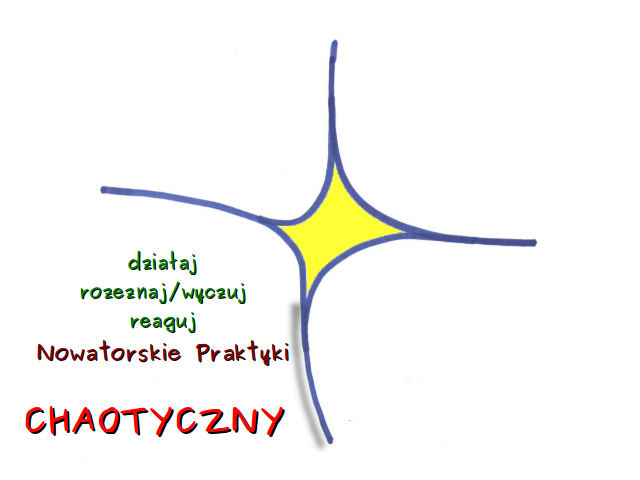 Dla porządku należy wspomnieć o ostatniej kategorii w modelu Cynefin – kontekście chaotycznym. W takich sytuacjach nie ma zależności przyczyna – skutek. Nie jest ona dostrzegalna również w retrospektywie. Podejmowanie decyzji w takich problemach polega na podjęciu działań nawet przed głębszym rozeznaniem sytuacji. Przykładem (w temacie finasowym) może tu być reakcja giełdy nowojorskiej na zamachy 11 września 2001r. Pierwszym krokiem osób odpowiedzialnych za tę instytucję w sytuacji kryzysowej było zamknięcie sesji na 4 dni. Dopiero potem był czas na zastanowienie.
Dla porządku należy wspomnieć o ostatniej kategorii w modelu Cynefin – kontekście chaotycznym. W takich sytuacjach nie ma zależności przyczyna – skutek. Nie jest ona dostrzegalna również w retrospektywie. Podejmowanie decyzji w takich problemach polega na podjęciu działań nawet przed głębszym rozeznaniem sytuacji. Przykładem (w temacie finasowym) może tu być reakcja giełdy nowojorskiej na zamachy 11 września 2001r. Pierwszym krokiem osób odpowiedzialnych za tę instytucję w sytuacji kryzysowej było zamknięcie sesji na 4 dni. Dopiero potem był czas na zastanowienie. 
Podsumowując, tradycyjne rozwiązania BI doskonale sprawdzają się w trudnych problemach. Każdy może wybrać odpowadającą sobie dobrą praktykę. Natomiast w sytuacjach złożonych, a sprawne radzenie sobie z nimi jest podstawą budowy przewagi konkurencyjnej, potrzebujemy narzędzi, które będą wspierać masowe gromadzenie danych bez czynienia założeń, co do spodziewanych wyników. Takiego oprogramowania nie można kupić “z pudełka”. Jest ono wynikiem współpracy pomiędzy klientem a firmą tworzącą oprogramowanie. Domena złożona, to miejsce gdzie taka firma jak TouK może pomóc.
