The Distributed Monolith term surely has a bad press. When you read through blogs and conference talks I’m sure you’d better build a “traditional” monolith rather that a distributed one. If you go with the latter, it means you tried to build microservices but you failed. And now your life is sad and full of pain ;) In this post I’d like to describe our case, when we built something like distributed monolith intentionally, with quite a pleasant final experience.
In my opinion the key to microservices is in the Conway’s Law. Looking from that perspective you’d think that primary use-case for microservices is large organizations with in-house IT department with many small teams, working independently, with large control over their part ot the system. But this doesn’t cover the full spectrum of software development market ;)
When you are a software house you deal with various type of projects. This includes maintenance, rewrite part of a large system and – last but not least – developing new systems from scratch. But the development process is much different than in-house IT: we use small, versatile teams (up to 10 people), not tight stick to roles like webdev, tester (developers, not programmers). There are no two identical projects for us: every customer has its own needs, tools, infrastructure, procedures, etc. (see http://ericsink.com/No_Programmers.html)
If you plan your system architecture you often try to do some checklist that can help you make the best choice. I think the most interesting question from it is:
Is there a part of the system that a single person, or small team, operates independently inside of?
The usual response for a software house is “Hmm… No”. So are we forced to always build monoliths?
The good parts of monolith
Let’s think first what could be the good parts of monolithic architecture, especially for a small team inside a software house:
Simple communication model
When you want to deliver fast, you have to reduce overhead. If your customer ask for a feature, telling him that you first have to investigate how to make your microservices talk to each other could be not acceptable. Also, having less service-to-service communication, makes monitoring and debugging in production a lot easier. It’s different when you build a large microservice stack for a big organization – you surely convinced business owners that you need some time to invest in tools and infrastructure and they have to wait for it to be done before features arrive ;)
Single repository
At software houses, we usually have a lot of freedom choosing CI/CD tooling, some team go with full-stack Gitlab, some prefer Gerrit + Jenkins, some work on customer’s infrastructure. We don’t have repeatable, complicated build pipeline for every project – usually just running tests, make some static code analysis (with Sputnik), sometimes push Docker images somewhere. It’s just easy to have just one repository, not having to setup multiple independently.
Single data source
This is also not constant across projects, but most of them need just one data source, possibly just RDBMS (Postgres) to store business data. It’s easy to administer, manage, migrate. If you want a bit less coupling between parts of the system, separate database schemas for a start could be enough.
Simple deployment infrastructure
Just like above, from deployment perspective, the simplest – the better. Your customer doesn’t want you to spend 3 weeks setting up a Kubernetes cluster. If you can go with plain Docker without dedicated orchestration – go with it. For us – AWS ECS with some home-made automation worked really fine.
The good parts of microservices
On the other hand, while building monolith may have many good parts, it can also be really painful. I think that there are numerous advantages you’ll get from splitting the whole system into few smaller parts. The key is having multiple deployment units, which really gives you benefits:
Resource separation
Bugs happen. It is obvious that your system will someday fail on production. The real question is what happens then? How your system deals with errors? If you use shared resources like database or http client connection pools, one, even not critical part of your system, may cause a full system outage. That’s why splitting your system into few smaller applications matters. You (and your customers) can probably live even if one of the minor functionalities fails.
Independent scaling
It is also good when your system can scale. It’s better when you can scale parts of your system independently. Some of features are massively used and business critical – and you want to run them in high-available mode with possibility to add instances on the fly when traffic increases. But also you have some other parts (e.g. backoffice) that is not heavily used with often zero traffic after working hours. With multiple applications instead of monolith it’s easier to achieve independent scaling.
Network separation
Usually parts of a big system are used from different places. You have some public services (e.g. mailing service), othen with both sides communication (with webhooks). On the other hand – a back-office part shouldn’t be exposed publicly, best hidden in a VPN to a customer’s office. Having these parts separated makes it easier to put them in different networks and then setup a particular policy of each part.
Separate configuration
Defining proper authentication configuration for Java (even in Spring) app could be hard. I guess that defining multiple authentication models (e.g. logged users, internal features for call-center people and public service calls) for different parts of a monolithic application could be a hell. Splitting a monolith into several deployment units, each with separate authentication configuration, may save you many hours of debugging magical untestable code provided by your framework.
Technology experiments
It’s really bad for a project if you’re stick to a legacy technology. Having thousands of lines written in 90’s Javascript framework could be really demotivating for developers. When you have few smaller deployment units, it’s much easier to play with technology experiments. You can either write the whole small part in some crazy technology (we use Elm for a small frontend piece) or try to upgrade some important library just in one place (we switched to 4.x Redux router in smaller application before upgrading the bigger one).
Taking best from two worlds
In our case, we think that we took the best from two approaches. We had small team (in peak 8 people), working on a single Git repository. We delivered 10 separate applications, all using the same datasource (Postgres). We used Kotlin + Spring Boot on backend, and React for frontend. We used Gradle modules to split the backend code into reusable parts, and Spring Boot apps just picked the needed pieces.
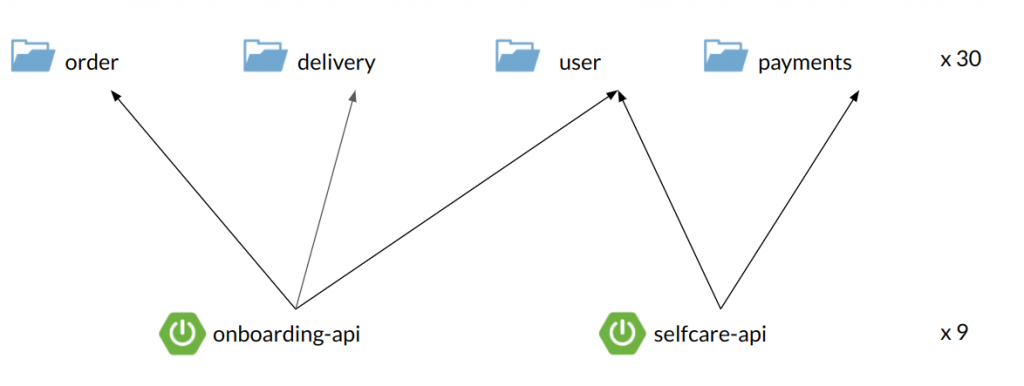
We packed the apps into Dockers, built with Gitlab CI pipelines and used Amazon ECS for container orchestration (with a small API gateway based on Nginx and Consul).
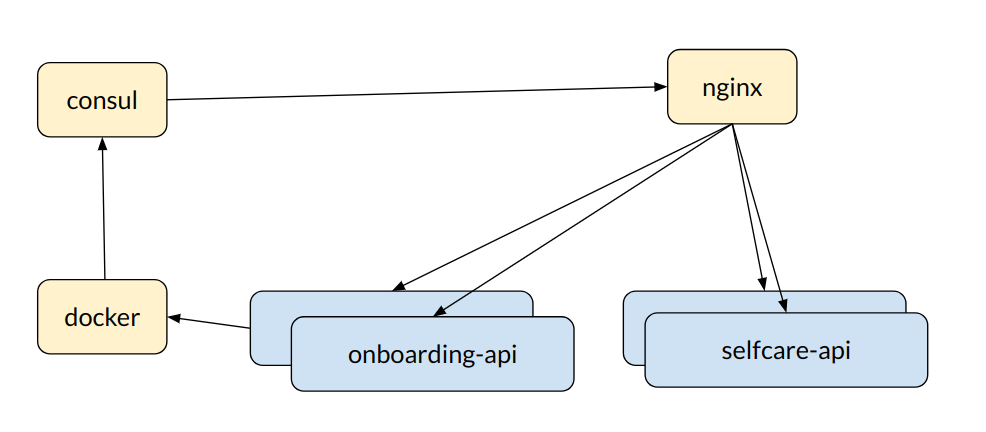 There was no inter-process (HTTP etc.) communication between the apps – we just used modules API for synchronous calls (mostly queries) and Quartz tasks for asynchronous commands. We also had ELK stack for logging and tracing.
There was no inter-process (HTTP etc.) communication between the apps – we just used modules API for synchronous calls (mostly queries) and Quartz tasks for asynchronous commands. We also had ELK stack for logging and tracing.
To be honest, we were 90% happy. The remaining 10% of things that didn’t work well included:
- many small modules – we had some performance problems with Intellij at the beginning with indexing all the small modules
- cyclic dependencies – sometimes we discovered cycling dependencies between these modules; on the other hand – it helped us to remove some flaws from our design
- tight coupling – our apps were designed by API (consumer) perspective, rather than clean DDD, bounded context thinking; but separate modules could help with this – e.g. a new delivery system was developed as separate part, with its own database schema
- “all-at-once” deployment – and yes, having just 1 database, we often had to deploy multiple applications at once.
Having said that, I think that we managed a good balance between two worlds. We didn’t struggle with massive infrastructure and tooling, working with different repositories and data sources. We were able to go as fast as we built a single-repository monolith application. But we had some parts separated, with their own configuration/boilerplate, ready to be deployed and scaled independently.